How to Determine Which Distribution Fits My Data Best
Load data using the Load Data button. The cost of not meeting the assumptions could be high at.
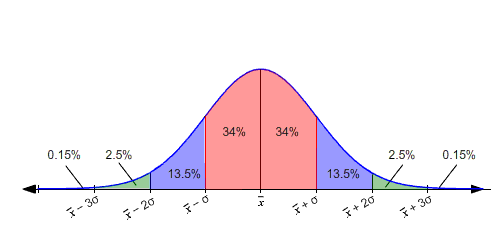
Normal Distribution Of Data
Given the higher p-value and significant LRT P value we can pick the 3-Parameter Weibull distribution as the best fit for our data.
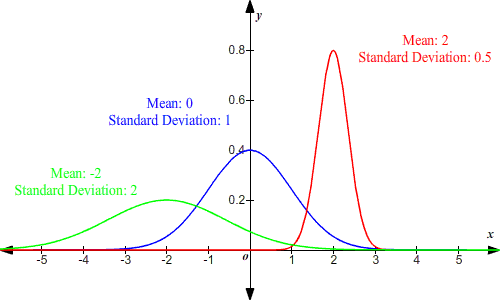
. For quick and visual identification of a normal distribution use a QQ plot if you have only one variable to look at and a Box Plot if you have many. Remember that several of these distributions have restrictions on the value of the observations. However its rare to.
If the model fit to the data were correct the residuals would approximate the random errors that make the relationship between the explanatory variables and the response variable a statistical relationship. Library fitdistrplus descdist. Based on the sumsquared_error criteria the best-fitted distribution is the normal distribution.
For example negative values are invalid for the exponential distribution. There also visual techniques that help you decide which distribution is best. Import numpy as np from distfit import distfit Generate 10000 normal distribution samples with mean 0 std dev of 3 X nprandomnormal0 3 10000 Initialize distfit dist distfit Determine best-fitting probability distribution for data distfit_transformX.
I have a data of warehouse. Use goodness of fit techniques to help determine which distribution fits your data best. Save the Main_FitDistribution_GUIfig and Main_FitDistribution_GUIm files at the same directory.
Well if you accept that the evidence is strongest for the model with the greatest ie least negative likelihood then the gamma distribution is the model which has the strongest evidence among the ones you considered. Many textbooks provide parameter estimation formulas or methods for most of the standard distribution types. You can test the hypothesis that your data were sampled from a Normal Gaussian distribution visually with QQ-plots and histograms or statistically with tests such as DAgostino-Pearson and Kolmogorov-Smirnov.
The uncertainty is quite large but your data could be represented by a lognormal or gamma or Weibull distribution according to this plot. Integers or whole numbers such as the number of ducks observed in a pond or continuous eg pH measurements of solutions. The difference between the sample and the fit.
First determine if your data are discrete ie. There i have no of pallets coming at particular times. Currently i am working on my thesis.
That will restrict the procedure to only the distributions of interest. Evaluate all your fits and pick the best one. Apply the fit method.
You can also use PRINTALL to find out more information about each fit. The R code used is. After the distributions are fitted it is necessary to determine how well the distributions you selected fit to your data.
The file should be a text file with 1 column containing the data. Choose Stat Quality Tools Individual Distribution Identification. Its a good practice to know your Data once you start working on it.
The attached file DataExampletxt contains data in a legal format. F Fitterdata distributions get_common_distributions ffit fsummary. Our Data Suppose we have sample of 100 data points.
The solution of this problem involves the use of certain algorithms implemented in specialized software. This shows the distribution of your data in a skewness 2 -kurtosis space data is the big blue point the orange points are bootstrapped from your data. Therefore if the residuals appear to behave randomly it suggests that the.
Hello All Since i have not suffiecient knowledge in statistics i am not able to find a distribution for my data. Heres how you use Individual Distribution Identification to choose the distribution that best fits your current data. Create a Fitter instance by calling the Fitter Supply the data height and distributions list if you have a basic idea of the distributions that might fit your data.
As a statistical test to confirm your hypothesis use the Shapiro Wilk test. Specify the column of data to analyze and the distributions to check it against. Run the Main_FitDistribution_GUIm file.
Distribution parameters based on your sample data. Once a distribution type has been identified the parameters to be estimated have been fixed so that a best-fit distribution is usually defined as the one with the maximum likelihood parameters given the data. We identified this distribution by looking at the table in the Session window but Minitab also creates a series of graphs that provide most of the same information along with probability plots.
Probability plots are a great way to visually identify the. This can be done using the specific goodness of fit tests or. The next step is to start fitting different distributions and finding out the best-suited distribution for the data.
Many Algorithms like Linear Regression assumes variables to follow a particular distribution. It is the most powerful test which should be the decisive argument. These includes examining a histogram with the distribution overlaid and comparing the empirical model to the theoretical model.
For example from Morning 6O clock the process starts and ends at 6O clock next day. Use a histogram if you need to present your results to a non-statistical public. This can be done by performing a Kolmogorov-Smirnov test between your sample and each of the distributions of the fit you have an implementation in Scipy again and picking the one that minimises D the test statistic aka.
A Gentle Introduction To Statistical Data Distributions
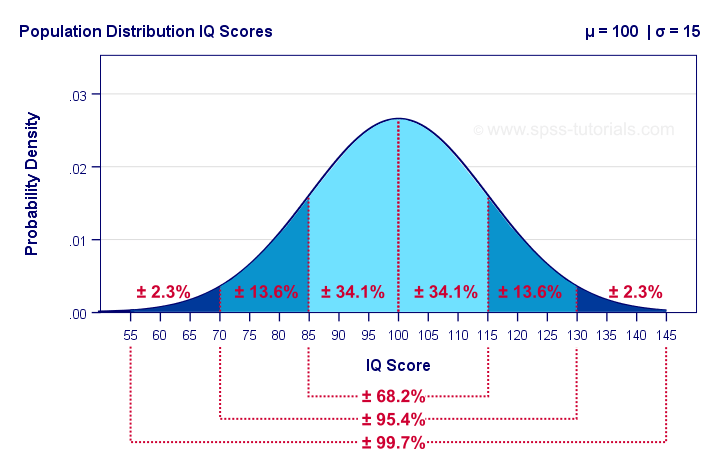
Normal Distribution Statistics The Ultimate Guide
Normal Distribution Of Data
No comments for "How to Determine Which Distribution Fits My Data Best"
Post a Comment